HBase
Apache HBase™ is the Hadoop database, a distributed, scalable, big data store.
- NoSQL
- Schemaless
- 가용성과 확장성
- Region 서버만 추가하여 확장성 및 가용성 확보가 용이
- 단, 특정 Region 서버에 부하가 집중되면 성능저하가 발생 -> 로우키 설계가 중요
- Apache Phoenix: Add SQL Layer
Column Family
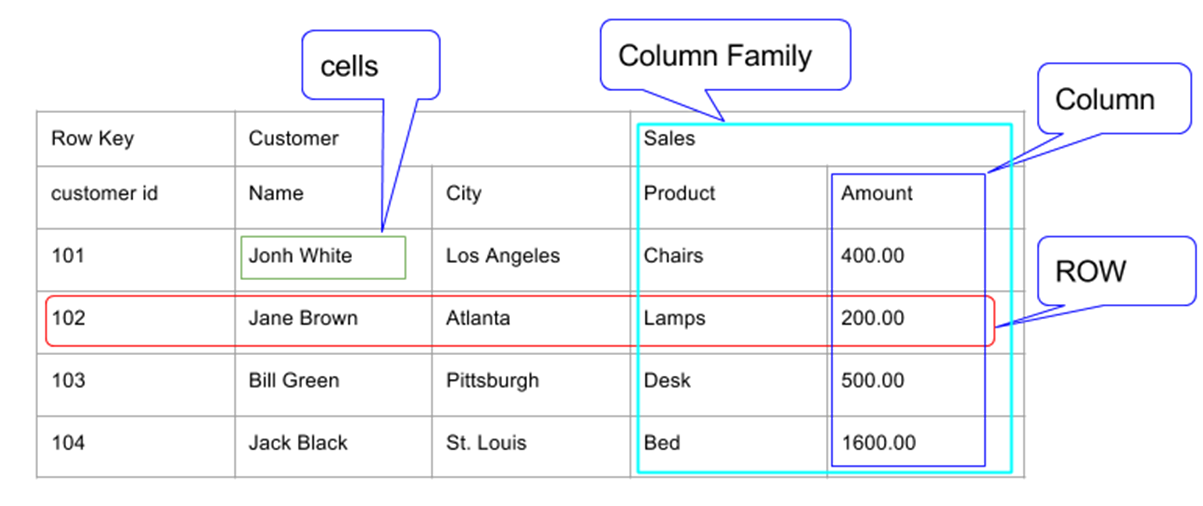
- 이 테이블은 Customer와 Sales 두 개의 컬럼 패밀리를 가지고 있다.
- Customer 컬럼 패밀리는 Name과 City 두 개의 컬럼을 가지고 있다.
- Sales 컬럼 패밀리는 Product와 Amount 두 개의 컬럼을 가지고 있다.
- Row는 Row Key, Customer CF, Sales CF로 구성된다.
특징
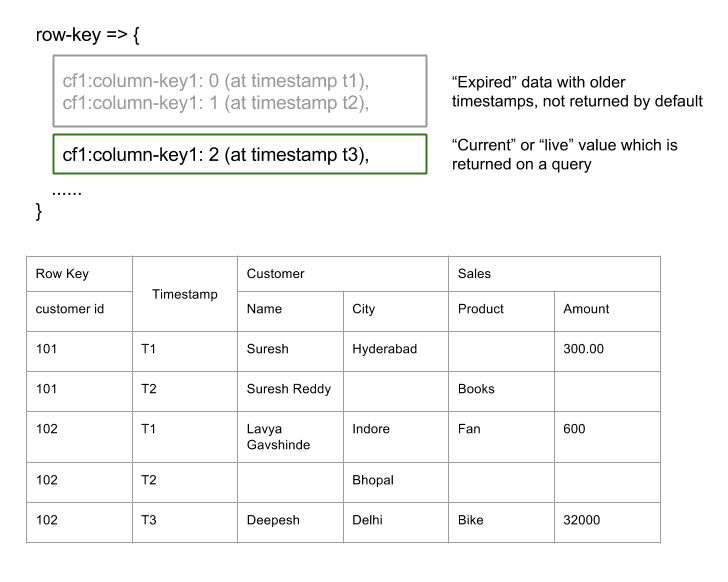
- Sparse: HBase는 sparse matrix(희소행렬)방식으로 데이터를 저장 할 수 있다. 예컨데 굳이 모든 필드에 값을 채울 필요가 없다는 얘기다.
- Column Oriented: RDBMS는 row 단위로 데이터를 저장한다. 하지만 HBase는 Sparse하기 때문에, 컬럼 단위로 데이터를 읽고 쓸 수 있다.
- Distributed: 테이블은 수백만개의 Row와 컬럼들로 구성된다. 이들 컬럼들은 쉽게 분산 할 수 있다.
- Versioned: 위 테이블은 Customer ID를 Row key로 사용하고 있다. 당연하지만 고객은 하나 이상의 물건을 구매할 수 있기 때문에 하나의 row key에 여러 개의 row를 저장 할 수 있다. 이 경우 Timestamp가 버전이 되며, 질의를 할 경우 가장 최근 timestamp의 row를 읽어 온다.
- Non-relational: 관계형 데이터베이스의 ACID 속성을 따르지 않는다.
Architecture
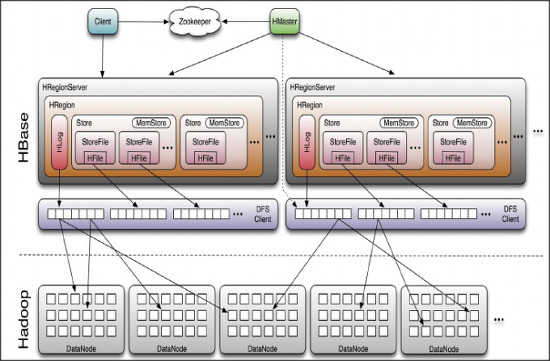
- HMaster
- RegionServer 와 META 데이터 관리
- HRegionServer
- Region 관리
- HResion
- 테이블 데이터의 부분집합이며, 수평확장의 기본단위
- HLog
- HFile
HBase HMaster
각 테이블의 데이터는 HRegionServer가 관리하며, 전체 클러스터는 HMaster가 관리한다.
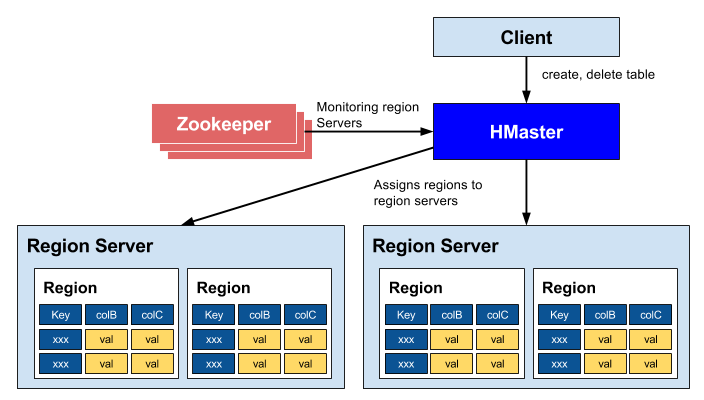
- 리전 서버들을 조정
- 리전의 시작을 관리
- 클러스터에 있는 모든 리전 서버들을 모니터링
- 관리 기능
- 테이블의 생성, 삭제, 업데이트
HBase Catalog Tables
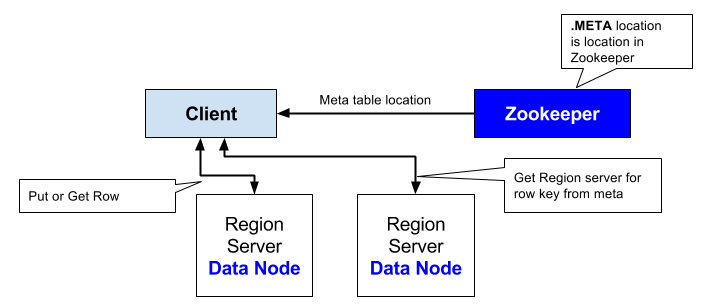
- 클라이언트는 주키퍼의 META 테이블을 서비스하는 리전 서버의 호스트 정보를 읽어온다.
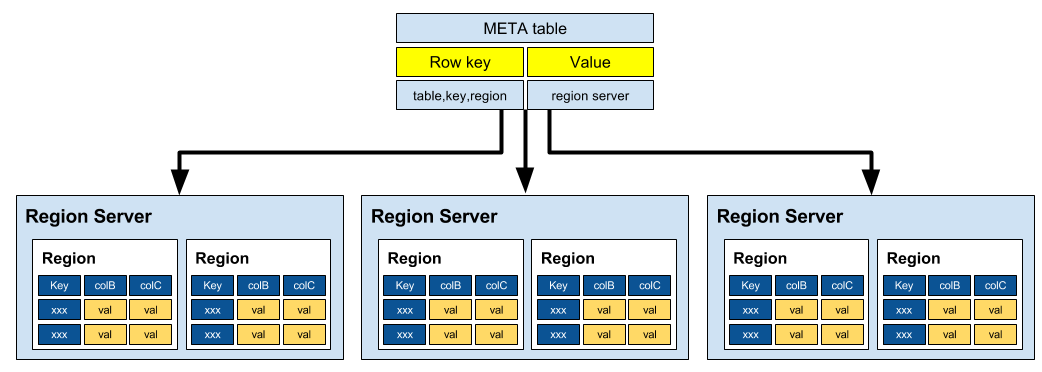
- META 테이블
- 클러스터에 포함된 모든 리전정보 저장
- -ROOT-, .META.
데이터를 찾는 방법
- ZooKeeper -> -Root- -> Region Server -> .META. -> Region -> Row
HBase Region Server
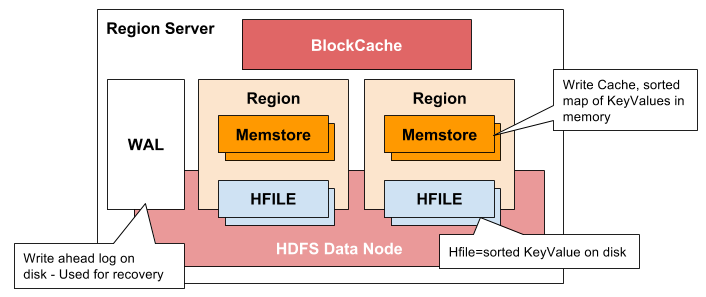
- 클라이언트와 통신을 하고 데이터 관련 연산을 관리
- 내부 region의 읽기와 쓰기 요청을 관리
- Region Server Components
- WAL(Write Ahead Log)
- 데이터 저장 실패를 복구하기 위해서 사용
- BlockCache
- 읽기 캐시
- MemStore
- 쓰기 캐시
- 각 리전의 컬럼 패밀리당 하나
- HFile
- WAL(Write Ahead Log)
HBase Minor Compaction
- 데이터를 입력하다 보면 여러 개의 작은 HFile들이 만들어진다.
- 파일들이 많아지면 성능이 떨어질 수 있는데,
- Minor compaction은 여러 개의 HFile들을 하나의 큰 HFile로 통합
- HFile에 저장된 데이터는 정렬되어 있으므로 merge sort를 이용해서 빠르게 합병
HBase Major Compaction
- Major compaction은 리전에 있는 모든 HFiles들을 모아서 컬럼당 하나의 HFile로 만든다.
- 이 과정에서 필요없는 셀, 시간이 초과된 셀등을 제거해서 전반적인 읽기 성능을 높인다.
- 대량의 파일들에 대한 읽기/쓰기 작업이 일어나기 때문에 디스크 I/O와 트래픽 증가가 발생
- Major compaction은 자동으로 실행하도록 예약
- 서비스에 미치는 영향을 최소화하기 위해서 주말이나 야간으로 스케줄링
HBASE vs RDBMS
| HBase | RDBMS |
|---|---|
| 스키마가 없다. column families만으로 이용 | 테이블의 구조를 기술하는 스키마 |
| 수평적으로 확장성이 있어 큰 테이블에 적합 | 확장하기 어려우며, 크기가 작은 테이블을 위해 생성 |
| Transaction이 존재하지 않음 | Transaction이 존재 |
| 비 일반화된 데이터 | 일반화된 데이터 |
| 덜 구조화된 데이터가 적합 | 구조화된 데이터에 적합 |
| get / put / scan 등 | SQL |
| MapReduce Join 활용 | Join에 최적화 됨 |
| RowKey만 인덱스 지원 | 임의 컬럼에 대한 인덱스 지원 |
| 초당 수십만건 Read/Write | 초당 수천건 Read/Write |
| 단일로우 트랜잭션 보장 | 다중 로우 트랜잭션 보장 |
HBase 사용법
1. Connect to HBase
$ ./bin/hbase shell
hbase(main):001:0>
2. Create a table
hbase(main):001:0> create 'test', 'cf'
0 row(s) in 0.4170 seconds
=> Hbase::Table - test
3. List Information About your Table
hbase(main):002:0> list 'test'
TABLE
test
1 row(s) in 0.0180 seconds
=> ["test"]
4. Put data into your table.
hbase(main):003:0> put 'test', 'row1', 'cf:a', 'value1'
0 row(s) in 0.0850 seconds
hbase(main):004:0> put 'test', 'row2', 'cf:b', 'value2'
0 row(s) in 0.0110 seconds
hbase(main):005:0> put 'test', 'row3', 'cf:c', 'value3'
0 row(s) in 0.0100 seconds
5. Scan the table for all data at once.
hbase(main):006:0> scan 'test'
ROW COLUMN+CELL
row1 column=cf:a, timestamp=1421762485768, value=value1
row2 column=cf:b, timestamp=1421762491785, value=value2
row3 column=cf:c, timestamp=1421762496210, value=value3
3 row(s) in 0.0230 seconds
6. Get a single row of data.
hbase(main):007:0> get 'test', 'row1'
COLUMN CELL
cf:a timestamp=1421762485768, value=value1
1 row(s) in 0.0350 seconds
7. Disable a table.
hbase(main):008:0> disable 'test'
0 row(s) in 1.1820 seconds
hbase(main):009:0> enable 'test'
0 row(s) in 0.1770 seconds
8. Drop the table.
hbase(main):011:0> drop 'test'
0 row(s) in 0.1370 seconds
9. HBase scan option
사용법 : scan “$TABLE_NAME”, {$OPTION => $VALUE} (옵션 여러개 가능)
# 1) LIMIT : 출력할 row 수 제한
scan "$TABLE_NAME", {LIMIT => 10}
# 2) STARTROW / STOPROW : 출력할 row 범위 제한
scan "$TABLE_NAME", {STARTROW => "$START_KEY", STOPROW => "$STOP_KEY"}
# 3) COLUMNS : 원하는 column 출력(column은 columnFamily:columnQualifire 형태, CF:CQ)
scan "$TABLE_NAME", {COLUMNS => "$CF:$CQ"}
# 4) TIMERANGE : 특정 타임스탬프 사이의 값 조회
scan "$TABLE_NAME", {TIMERANGE => [ts1, ts2]}
# 5) ROWPREFIXFILTER : 특정 row key를 조회
scan "$TABLE_NAME", {ROWPREFIXFILTER => "$ROWKEY"}
10. HBase Filters
사용법 : scan “$TABLE_NAME”, {FILTER => “$filtername(‘$value’)”}
scan "$TABLE_NAME", {OPTION => VALUE, FILTER => "FILTERNAME('VALUE')"}
11. Exit the HBase Shell.
hbase(main):006:0> quit
sample.txt
create 'test', 'cf'
list 'test'
put 'test', 'row1', 'cf:a', 'value1'
put 'test', 'row2', 'cf:b', 'value2'
put 'test', 'row3', 'cf:c', 'value3'
put 'test', 'row4', 'cf:d', 'value4'
scan 'test'
get 'test', 'row1'
disable 'test'
enable 'test'
HBase Java Client Example
HBase Data Structure
Family1:{
'Qualifier1':'row1:cell_data',
'Qualifier2':'row2:cell_data',
'Qualifier3':'row3:cell_data'
}
Family2:{
'Qualifier1':'row1:cell_data',
'Qualifier2':'row2:cell_data',
'Qualifier3':'row3:cell_data'
}
HBase Client Maven Dependency
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase</artifactId>
<version>${hbase.version}</version>
<type>pom</type>
</dependency>
1. Connecting to HBase
hbase-site.xml
<configuration>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop01</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
</configuration>
Configuration config = HBaseConfiguration.create();
String path = this.getClass()
.getClassLoader()
.getResource("hbase-site.xml")
.getPath();
config.addResource(new Path(path));
HBaseAdmin.checkHBaseAvailable(config);
2. Createing a Database Structure
private TableName table1 = TableName.valueOf("Table1");
private String family1 = "Family1";
private String family2 = "Family2";
Connection connection = ConnectionFactory.createConnection(config)
Admin admin = connection.getAdmin();
HTableDescriptor desc = new HTableDescriptor(table1);
desc.addFamily(new HColumnDescriptor(family1));
desc.addFamily(new HColumnDescriptor(family2));
admin.createTable(desc);
3. Adding and Retrieving Elements
byte[] row1 = Bytes.toBytes("row1")
Put p = new Put(row1);
p.addImmutable(family1.getBytes(), qualifier1, Bytes.toBytes("cell_data"));
table1.put(p);
Get g = new Get(row1);
Result r = table1.get(g);
byte[] value = r.getValue(family1.getBytes(), qualifier1);
Bytes.bytesToString(value)
4. Scanning and Filtering
Filter filter1 = new PrefixFilter(row1);
Filter filter2 = new QualifierFilter(
CompareOp.GREATER_OR_EQUAL,
new BinaryComparator(qualifier1));
List<Filter> filters = Arrays.asList(filter1, filter2);
Scan scan = new Scan();
scan.setFilter(new FilterList(Operator.MUST_PASS_ALL, filters));
scan.addColumn(family1.getBytes(), qualifier1);
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
System.out.println("Found row: " + result);
}
5. Deleting Rows
Delete delete = new Delete(row1);
delete.addColumn(family1.getBytes(), qualifier1);
table.delete(delete);
Apache Phoenix
Phoenix is an open source SQL skin for HBase.
You use the standard JDBC APIs instead of the regular HBase client APIs to create tables, insert data, and query your HBase data.
특징
- HBase 데이터에 대한 빠른 접근이 가능
- MapReduce를 사용하지 않고 SQL 쿼리를 Native HBase 명령어로 컴파일하여 수행
- 추가적인 서버가 필요하지 않기 때문에 비교적 가벼움
- 기존에 존재하는 HBase 테이블과의 매핑이 가능
장점
- JOIN
- Paging
- OFFSET & LIMIT (ex. LIMIT 10 OFFSET 10)
- Secondary Index
- Salted Tables
- Splitting: pre-split on salt bytes boundaries
- ex. new_row_key = (++index % BUCKETS_NUMBER) + original_key
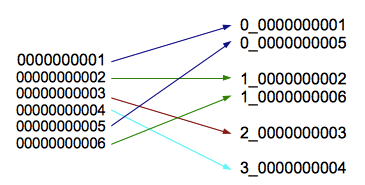
- ex. new_row_key = (++index % BUCKETS_NUMBER) + original_key
- Row Key Ordering: phoenix.query.rowKeyOrderSaltedTable=true
- CREATE TABLE table (a_key VARCHAR PRIMARY KEY, a_col VARCHAR) SALT_BUCKETS = 20;
- Splitting: pre-split on salt bytes boundaries
Apache Phoenix Java Client Example
Phoenix Driver Maven Dependency
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-core</artifactId>
<version>4.13.1-HBase-1.2</version>
</dependency>
PhoenixExample.java
public class PhoenixExample {
public static void main(String[] args) {
// Create variables
Connection connection = null;
Statement statement = null;
ResultSet rs = null;
PreparedStatement ps = null;
try {
connection = DriverManager.getConnection("jdbc:phoenix:demo");
statement = connection.createStatement();
statement.executeUpdate("create table javatest (mykey integer not null primary key, mycolumn varchar)");
statement.executeUpdate("upsert into javatest values (1,'Hello')");
statement.executeUpdate("upsert into javatest values (2,'Java Application')");
connection.commit();
ps = connection.prepareStatement("select * from javatest");
rs = ps.executeQuery();
System.out.println("Table Values");
while (rs.next()) {
Integer myKey = rs.getInt(1);
String myColumn = rs.getString(2);
System.out.println("\tRow: " + myKey + " = " + myColumn);
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
try {
ps.close();
rs.close();
statement.close();
connection.close();
} catch (Exception e) {
}
}
}
}
